

A product model for a collaborative CDP & valmi.io Open Source Data Activation (reverse ETL) platform built over the airbyte protocol is embracing it.
“It was the age of wisdom, It was the age of foolishness…” The age of smartphone apps was dawning. Wisdom stayed with the few who owned the app stores. Foolish were those who built apps for these stores. We started an indie game studio circa 2011 and engineered one of the first few games for the Android market. Now, there are probably a million or two of them on the market. We were certainly early and managed to reach over 25 million users across our portfolio. While most of our game portfolio waned due to increasing competition and the whims of the duopoly, one still shines. And, it generates a lot of data, a lot of user data.
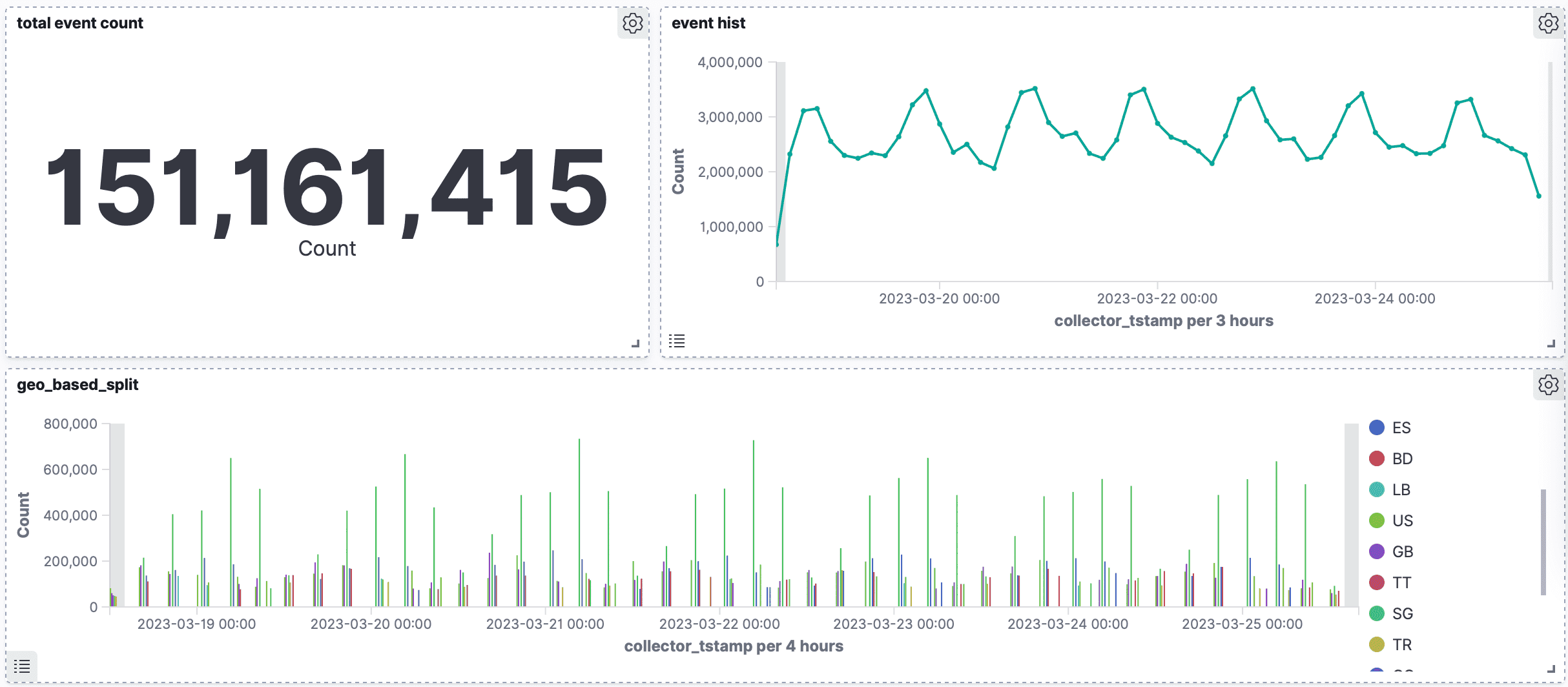
The event volume is huge — the picture shows aggregated events for the last seven days. Games generate a lot of events, but that does not necessarily correspond with revenue. We are toying with the idea of personalizing in-app purchases based on the user model to lift the revenue figures — use case #UC1 [A user model can simply be a giant table of users with their attributes]. Further, any new features we add also need product analytics support — use case #UC2. One can put to work a CDP like Segment, with its real-time profiles API, to tackle the personalization problem of UC1, and an off-the-shelf tool like Mixpanel helps with product analytics. They are great, simple to use, and allow self-serve to an extent. But, there are only a few problems — cost, privacy, and disjoint user models.
Given the massive volumes of data, it is fiendishly cost-prohibitive to pipe all the raw events to these SaaS tools. Additionally, in the sample event below, there is PII. That makes sending user data to third-party processors carry economic risk post-GDPR. What are we to do? The Sun has shone, and the warehouses have risen from the cloud. With their rise, data can be centralized within the boundaries of an organization, and the need for piping data to third parties stands obviated. Now, combine the idea of a CDP with a warehouse, and you have a warehouse-based CDP. It is becoming all the rage, and for good reasons. Indeed in a similar vein, we use Snowplow to track and load behavioral data into our warehouse.
{
"_source": {
"etl_tstamp": "2023-03-27T05:28:21.166Z",
"geo_latitude": 11.5583,
"contexts_com_tusk_player_context_1": [
{
"score": 10000,
"diamonds": 0,
"music": 1,
"tier": 1,
"level": 8,
"sound": 1,
"name": "<redacted>",
"xp": 90.40000000000003,
"sp": 158
}
],
"network_userid": "568fc8db-95c6-44c1-b2fb-e6ab041127da",
"geo_country": "KH",
"user_ipaddress": "27.x.x.x",
"geo_region": "12",
"geo_timezone": "Asia/Phnom_Penh",
"useragent": "snowplow/andr-1.7.1 android/12",
"event_name": "event",
"dvce_sent_tstamp": "2023-03-27T05:28:03.530Z",
"se_category": "ChipSelect",
"user_id": "<redacted>",
"geo_longitude": 104.9121,
"contexts_com_snowplowanalytics_snowplow_mobile_context_1": [
{
"osVersion": "11",
"osType": "android",
"deviceModel": "SM-T735",
"deviceManufacturer": "samsung",
"networkType": "offline"
}
],
"os_timezone": "Asia/Phnom_Penh",
"geo_location": "11.5583,104.9121",
"geo_city": "Phnom Penh",
"geo_region_name": "Phnom Penh"
}
...<redacted>...
}The move towards magnificent warehouses such as Snowflake was a fine one, but what of the chinks that erupted? Where was the simplicity of the earlier experience offered by the SaaS tools? At Rudderstack, which is a pioneer of warehouse-CDP and where I was fortunate to have played a part, I have quickly realized that any simple data use case requires a triad of personas — The Analytics Engineer, The data scientist, and The Operations Executive.
The origin of dependency hell! As the warehouse data is raw and a unified user model is a far cry from the raw data, the power shifted to the engineers, and executives are rendered dependent. Consider the earlier SaaS tools, and if we needed to target a user, in the UC1, with a personalized product, the executive using Segment’s CDP could ideally create a custom audience, add a new trait on the user model, and serve it with real-time API, all through a web user interface. With this, a personalized product can appear to the targeted user. If, however, machine learning predictions are required, Segment CDP has nothing to offer. They can possibly be hacked through its SQL traits. But this world was simple. In summary, the simplicity offered by previous tools has just evaporated by compensating with a warehouse-CDP for what these tools lacked.
Enter the much-touted Composable CDP. Supposedly, you buy ten different tools, one for each purpose — product analytics, marketing, and, maybe, a data lineage tool. Of course, we have dbt at the center — the open-source standard for transforming data in warehouses. Bazinga! Welcome to the composable CDP. My only reaction to that is — How do you sell old wine? Ummm… Get a new bottle. Granted, one silver lining here is that an organization can adopt an incremental approach to data. In other words, as the use cases grow with time, specialized tools can plug into the central data in the warehouse. But, how this solves the problem of simplicity and self-serve remains a mystery to me. What we wanted was a unified user model. We got somethin’ else.

So, What does a reimagining of the status quo look like? An enumeration of the constraints staring at us — data is to be centralized in the warehouse, the operational executives need their tools such as salesforce and braze as these tools are good at what they do, the analytics engineer gets to use the standard dbt transformation layer, and the data scientist his notebooks. This is a view from the triad — The Operations Executive, The Analytics Engineer, and The data scientist. In addition, an alternative view of the data flow involves the operations — Shape, Explore, Discover, and Activate.
From a use case standpoint, if we map the persona to the data flow operation, Shape (transform) sits squarely with the analytics engineer, and Explore and Discover are shared by all three. For example, the executive may want to explore audiences through UI. The data scientist may run a lot of analysis and discover a particular insight, such as churn propensity. Finally, the last leg, Activate, lies critically within the executive’s remit, including, for instance, piping the audience data into an advertising platform or a messaging platform like Braze. This immediately usable operation is where valmi.io introduces its Open Source Activation (reverse ETL) Platform.
A bright spot. Continuing with the use case standpoint, we have asked ourselves — “How do we let each persona succeed? How do we bind them all, even if it means trading off some functionality for simplicity?” We discovered that a trait, a user trait, is the primitive that binds the triad and leads them to collaborate. A trait is something that characterizes the user. A trait is part of the user model. A trait, for instance, indicates whether the user belongs to a custom audience or not — a boolean. It may show the churn propensity of the user or his LTV — a continuous variable. It may indicate which store he is a regular customer of — a categorical string variable. A trait could be computed or even predicted from the user event history. A trait needs to show its provenance — a kind of lineage. The tuple of traits forms the user model, and the tuple evolves over time, marking revisions for the user model.
The trait is something everyone is in service of.
- An analytics engineer creates a dbt model or extends one to generate a new trait, for instance, aggregated monthly revenue from the user.
- A data scientist creates a predictive model to generate a new predicted trait.
- An operational executive creates a custom audience by exploring the UI-based segmentation of users or by following a funnel path, thereby adding a new boolean trait to the user model.
A product that revolves around traits includes the ability for the analytics engineers to bring in dbt models, for a data scientist to schedule his notebook, and for operators to use UI to segment users based on traits and event history, to create new audience traits, and then to activate these audiences.
We believe this is the missing layer of the modern data stack and, with further refining, can bring together a CDP by orchestrating a multitude of best-of-breed tools. valmi.io aims to orchestrate these tools and lead the way here. Call this layer a collaborative CDP, a CDP kernel, or a CDP shim. Still need to assemble a jury to figure this out.
Data Activation (reverse ETL). While we move on to service the user trait and build a product around it, we have leveraged some of the best tools to create an Open Source Activation (reverse ETL) Platform. It is built over the airbyte protocol. dbt is the center piece of our source connectors, and duckdb for metrics. We engineered our orchestrator over dagster, and dagster dovetails perfectly with our vision of being a multi-persona tool. The platform is designed to be API-first, scalable, resilient to failure. We envision a world where a vibrant community of engineers develops around connectors — a world in which the power of the open-source platform draws on the collective mind to keep the fast-moving world of connectors functional and cost-effective.
We will write up architectural details of the activation platform of valmi.io, add more data sync modes, for instance, mirror mode, and add a few more connectors in the coming weeks. We will spec out more details of the valmi.io collaborative CDP. While we are at it, please try out your first sync here — the announcement of the day — https://cloud.valmi.io
Github Repo — https://github.com/valmi-io/valmi-activation
Checkout the demo sync from valmi.io.
valmi.io demo notifications to a slack channel