Outcome-Billing for the Era of AI Agents
AI agents are like workers - get paid when they deliver results.
Quickly onboard customers for your AI agents with outcome-based pricing.
Price AI Agents for the value delivered, not effort expended.

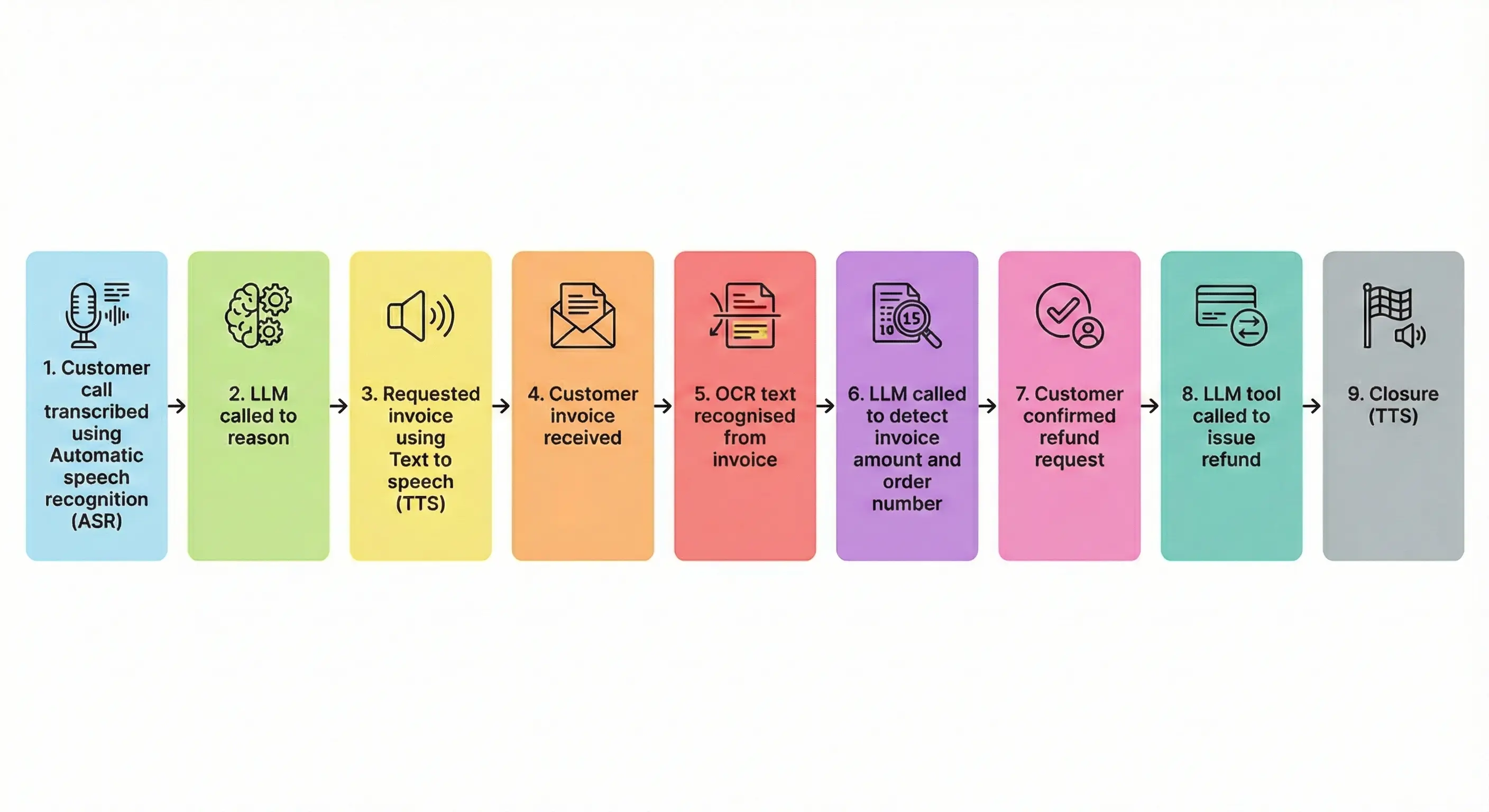
Engineered for revenue and product teams → less work for developers
Works with frameworks such as langgraph,crewai (coming soon),n8n (coming soon), and more.
All major LLM providers, such as OpenAI,Anthropic,Google are supported.






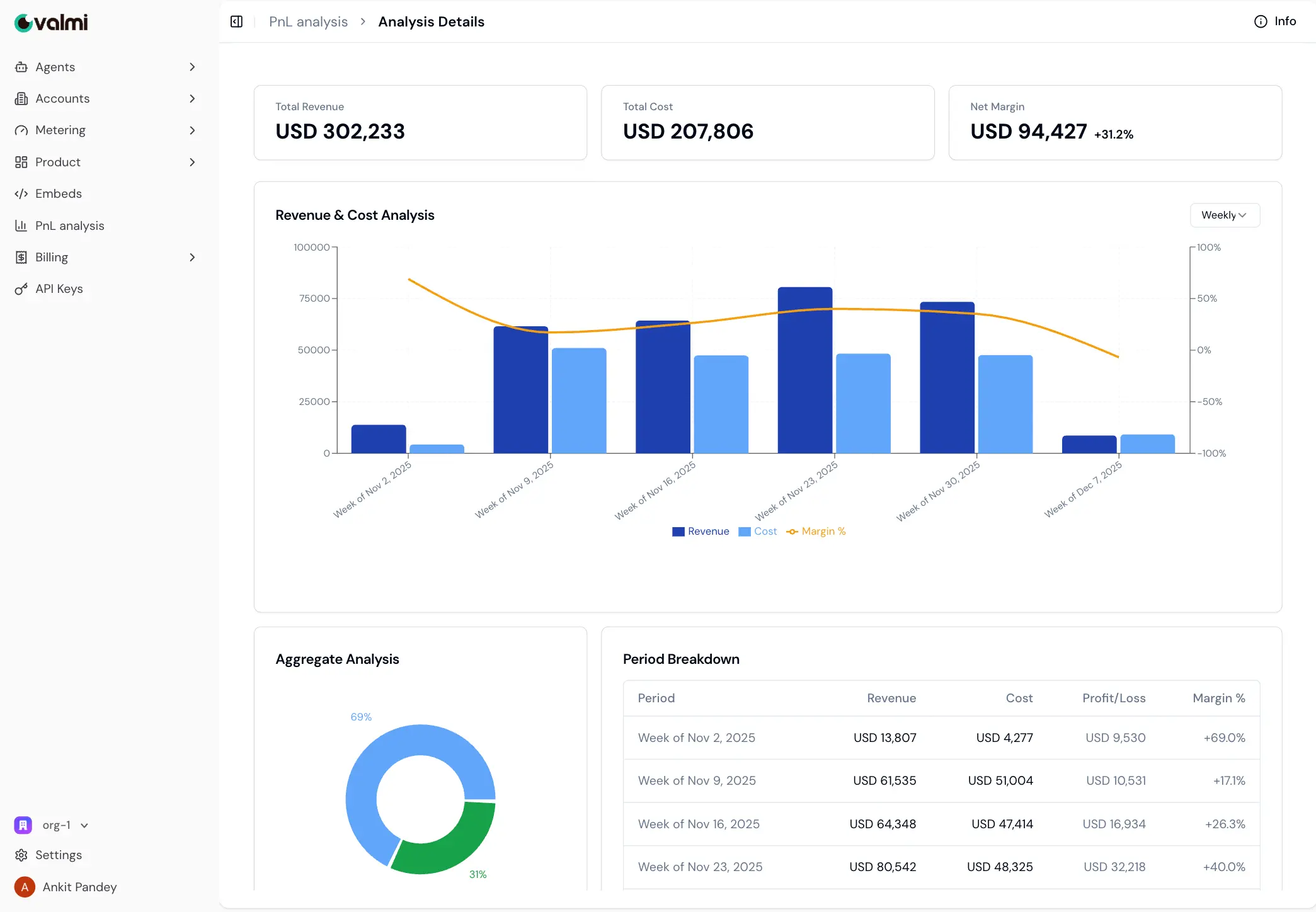
Your Revenue Engine for the Agentic Future
Valmi tracks every action and outcome so you can use flexible billing models for your AI agents, without building custom billing infrastructure.
Focus on your product. We handle the pricing, margins, and invoicing complexity of AI agents.
- ✓Flexible pricing: outcome, activity, or hybrid
- ✓Revenue insights across Customers
- ✓Smart, outcome-aware invoicing
- ✓Automatic margin tracking per agent instance
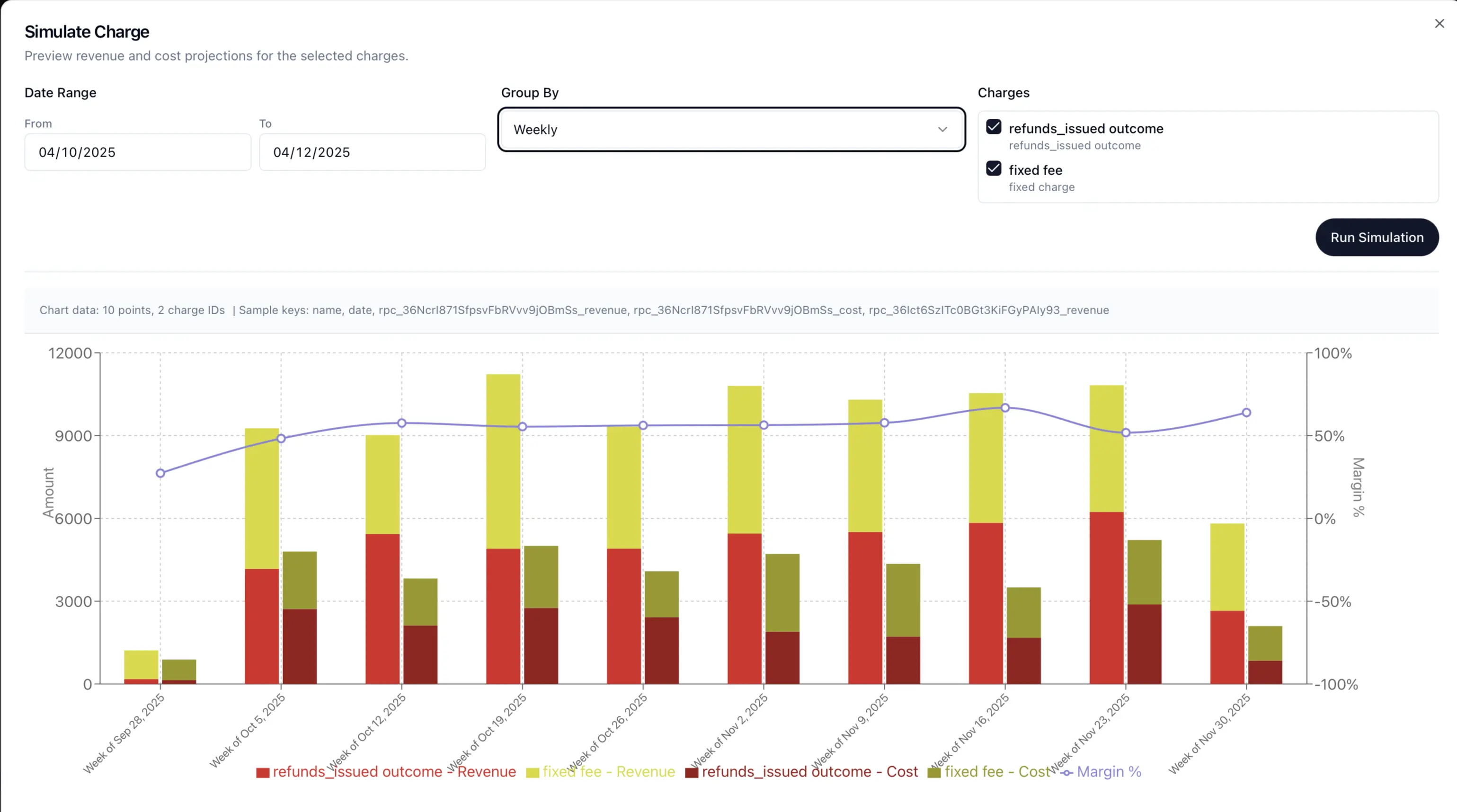
Pricing simulation
Test rate adjustments before going live.
Flexible billing
Demonstrate value using outcome-billing or, in the transition process, use other hybrid models
Account orchestration
Manage subscribers and invoicing in one place.
Payment infrastructure
Integrate with payment gateways such as Stripe, PayPal, and more.
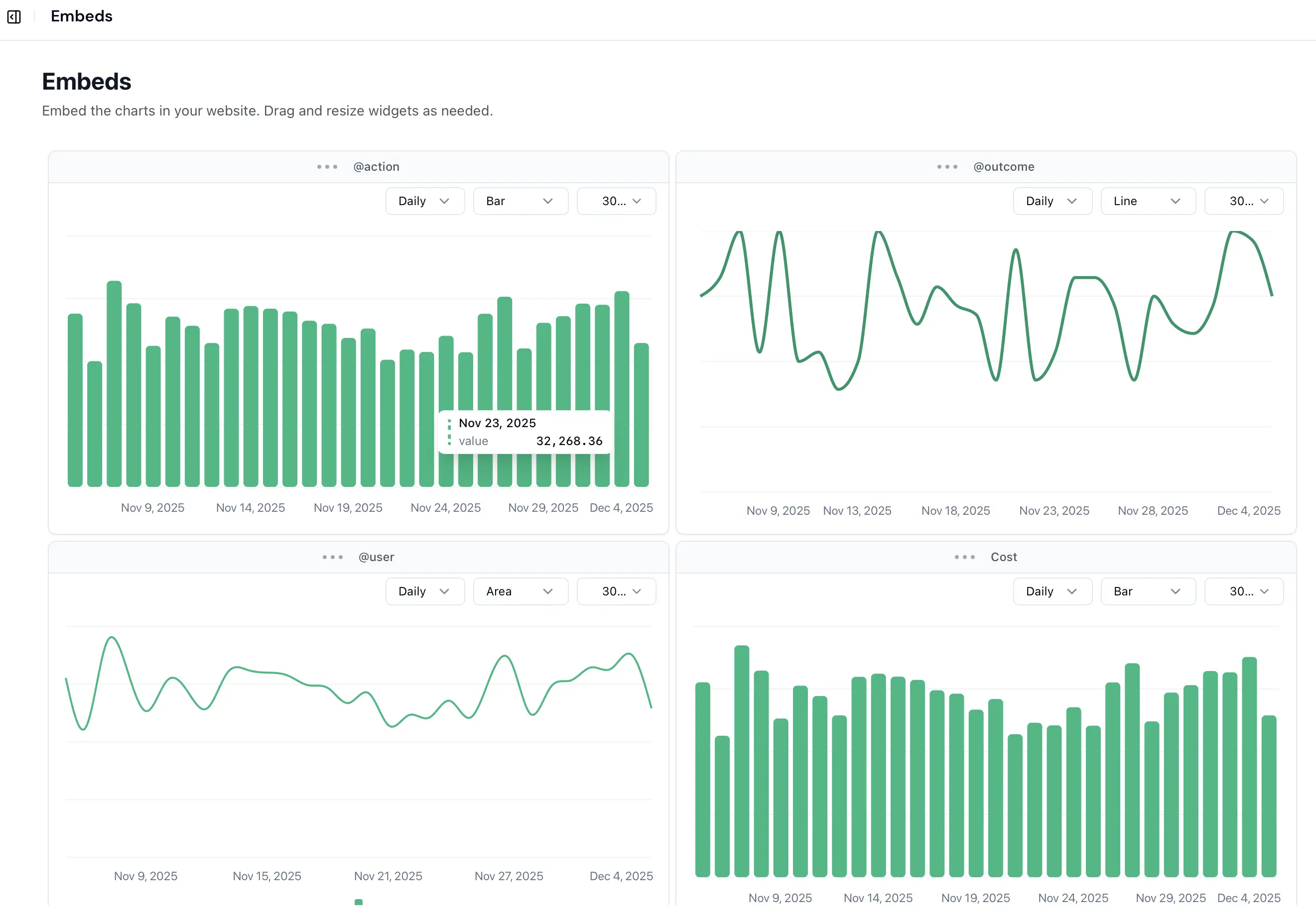
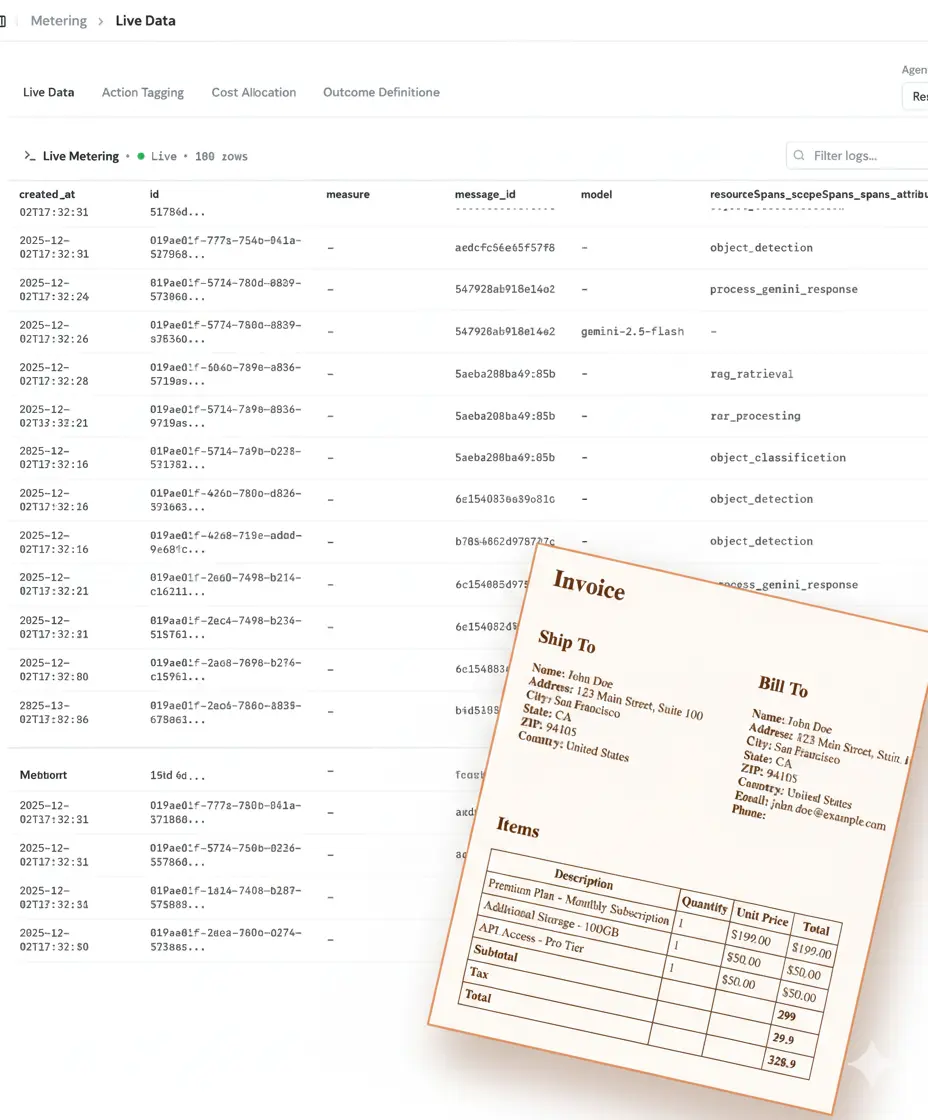
Monitor AI infrastructure spending with precision
Observe cost patterns, profitability metrics, and efficiency opportunities as they happen. Skip the burden of building custom dashboards.
- ✓OpenTelemetry-powered automatic tracking
- ✓Automatic margin & cost attribution
- ✓Real-time profitability insights
- ✓Unified view across all AI providers such as OpenAI, Anthropic, Google, and more
- ✓Customer dashboards with usage & outcome visibility
Used by innovative AI teams worldwide
Discover how organizations use Valmi to achieve financial clarity, strengthen margins, and simplify revenue operations.
Real Results.
“Valmi turns outcome-based pricing from a concept into real infrastructure. It’s a foundational layer for how AI and SaaS products can be monetized going forward.”

Ravi Dronamraju
Founder / Chief Investment Officer, Dhruva Fund
“As data and AI products become more autonomous, usage-based pricing alone stops making sense. Valmi gets the shift right, from measuring activity to measuring outcomes, providing a clean, extensible foundation to tie revenue directly to customer success.”

Soumyadeb Mitra
CEO & Founder
"I've deployed agentic AI at Nielsen to streamline operations, and the scope of work these agents handle is growing exponentially. Without proper billing infrastructure, companies risk budget black holes, both internally and for service providers. Valmi's transparency-first approach isn't just useful, it's a critical market need."

Nupur Kaudan
Nupur Kaudan - Global Transformation Director - Client Engagement BAU - NielsenIQ
“Valmi makes outcome billing practical. The APIs are clean, the model is intuitive, and it fits naturally into real production systems.”

Anudeep Sekhar
Lead Research Scientist, CMU, Biometrics Lab
Add billing to your AI stack in minutes
Begin with minimal Open-Source SDKs for Node.js (Coming soon), Python and Go (Coming soon). Implement quickly with clear guides and zero configuration complexity.
How Valmi surpasses legacy billing platforms
| LegacyLegacy billing | ||
|---|---|---|
| Flexible event-driven architectureEvent-driven architecture for real-time data | ||
| Unified usage tracking and billingUnified cost tracking and billing automation | ||
| Support for all agentic pricing modelsFlexible support for any pricing model | ||
| Real-time margin monitoringInstant profitability visibility | ||
| Agent performance trackingAI workflow performance monitoring |
Production-ready platform
Infrastructure designed for massive scale and operational sophistication.
Our SDKs are open-source. All our software is auditable and free-to-use and deploy. Docker deployable packages available on Github.
We have initiated the process to obtain the following certifications (IN PROGRESS).




Reliable availability
99.5% uptime commitment keeps your financial operations running as AI workloads reach mission-critical status.
Round-the-clock assistance
Continuous technical help with dedicated account teams for enterprise rollout and performance tuning.
Effortless setup
Expert implementation support guarantees smooth adoption across your current infrastructure.
Transparent Volume Pricing that Scales With You
Start at no cost and grow naturally—no hidden charges or unexpected bills.
Free
$0
Pro
Custom
Enterprise
Custom
*Product Launch - Forii - India's Sovereign AI Inference Platform *