
Data, Semantic Layers, and the LLMs
At Valmi.io, we recently introduced the "Prompt Page". This page empowers users to seamlessly get their desired metric data into spreadsheets (google sheets). Recognizing that spreadsheets are often where analytical work truly happens, our goal has been to provide essential data directly where it is most required.
With the foundation laid, we began to ponder: what comes next for analysts, marketers, and data enthusiasts? While metrics serve as a starting point, there are many more possibilities.
The Essence of Abstraction
We live in a world permeated by abstraction. For instance, the simple act of turning on a device is an abstraction of complex electronic flows. Similarly, the advanced information systems we depend on abstract the fundamental binary logic of electronic chips.

In the world of data, SQL acts as an abstraction layer over the datasets stored in relational databases. Over time, these layers of abstraction evolve, frequently taking new and sometimes innovative forms. One of the most promising advancements in this space is the emergence of Large Language Models (LLMs). Inspired by this trend, we at Valmi.io have dedicated our efforts towards iterating our products around LLM technology—aiming to harness their potential & look if we have any good use-case out of them. Here's an overview of our journey thus far.
Direct Queries to Your Database
Our exploration began with the question: Is it possible to communicate directly with our data using plain language? In our initial experiments, we began to learn about the current literature. We then tried to understand usage of metadata of the DB as context to the LLM, but as the size of a database increased—factoring in the number of tables and their complexity—the context required by LLMs also expanded. This often resulted in hallucinations related to column and table names that hindered accurate interpretation.
The challenges didn’t end there. LLMs might struggle to comprehend the contents of a column, especially when faced with ambiguous or non-intuitive column names. As a result, essential logical connections could not established by the LLM. The research community few of these problems:
- Providing example row data as contextual cues. (a reference to read: https://python.langchain.com/v0.1/docs/use_cases/sql/prompting/)
- Supplying descriptions of columns. (a reference to read: https://arxiv.org/abs/2408.04691)
- Generating column descriptions when they are absent.
- Embedding metadata about tables into a vector store for improved context.
To understand the effectiveness of text-to-SQL translation systems, we turned to prominent benchmarks:
- BIRD (Big Bench for Large-scale Database Grounded Text-to-SQL Evaluation): Offers a test accuracy of 72.39%.
- Spider: A complex, cross-domain dataset that boasts an impressive accuracy rate of 91.2%.
- Other benchmarks include WikiSQL and SParC.
Most notably, Spider has recently released a new dataset format—Spider 2.0—comprised of real-world enterprise-level SQL queries. Here, even the highest-performing LLMs, such as GPT-4, achieved merely a 6.0% success rate on its tasks. In contrast, they previously managed 86.6% on Spider 1.0 and 57.4% on BIRD, highlighting the unique challenges posed by this new dataset.
The Path Forward: Embracing Semantic Layers
Should we abandon the ambition of transforming text into SQL? Ofcourse not.
There is a defined recurring pattern in everyday data analysis tasks—data querying, aggregation, and filtering share discernible structures. By constraining these complexities, we can present a more approachable façade of the underlying data to end users. This concept is referred to as the Semantic Layer.
A semantic layer serves as a metadata-rich abstraction built upon source data (such as data warehouses or data lakes). By enriching the data model through defined rules, this layer simplifies the complexity of the data, allowing business users to understand & interact with the underlying data in a better way.
Instead of feeding LLMs with exhaustive information about the underlying datasets, we can focus on providing them with tailored semantic layer definitions—simplifying interactions while retaining accuracy and depth.
One such innovative product we've encountered is cube.dev, which embodies these principles effectively. To explore the intersection of semantic layers and LLM capabilities further, we have utilized our sample Shopify data as a case study.
Before diving deeper, we encourage you to familiarize yourself with Cube.dev’s offerings by visiting their Product Documentation and exploring their concepts of Data Modeling.
To facilitate data movement, we utilized Airbyte connectors to extract data from our Shopify store, which can be found in their Shopify Integration Documentation. This data was then populated into a PostgreSQL destination, documented here. For our initial exploration, we pulled only a few key streams: orders & customers.
Defining Cubes
With the data in place, we proceeded to define our cubes — structures designed to simplify and model relevant dimensions and measures for analysis. For instance, we created a cube that merges data from the orders and customers tables, capturing dimensions such as:
- updated_at
- city
- last_name
- customer_id
Additionally, we defined measures to quantify the data, including:
- average_order_value
- total_sales
- total_orders
To put this in perspective, the original orders table consists of an impressive 98 columns, while the customer table contains 32 columns. If we were to deploy the LLM directly with full access to these tables, it would require the model to retain information about all 130 columns, including their types and contextual meanings. This could be too much of context for an LLM. And there is no strong control over what columns are being queried when the LLM tries to write any query.
By defining our cube with precision, we can model the data to reflect only the dimensions and measures that are pertinent to our analysis needs. Below is an example of our orders.yml file that outlines the cube definition:
cubes:
- name: orders
sql_table: public.orders
data_source: default
joins:
- name: customers
relationship: many_to_one
sql: "{customer_id} = {customers.id}" # Join condition
dimensions:
- name: email
sql: "{CUBE}.email"
type: string
- name: updated_at
sql: CAST({CUBE}.updated_at AS DATE)
type: time
- name: city
sql: customer->'default_address'->>'city'
type: string
- name: last_name
sql: "{customers.last_name}"
type: string
- name: customer_id
# sql: "CAST({CUBE}.customer->>'id' AS BIGINT)"
sql: "{CUBE}.customer->>'id'"
type: number
primary_key: true
measures:
- name: total_sales
sql: "{CUBE}.subtotal_price"
type: sum
- name: average_order_value
sql: "{CUBE}.subtotal_price"
type: avg
- name: total_orders
type: count
- name: customers
sql_table: public.customers
data_source: default
dimensions:
- name: id
sql: "{CUBE}.id"
type: number
primary_key: true
- name: first_name
sql: "{CUBE}.first_name"
type: string
- name: last_name
sql: "{CUBE}.last_name"
type: string
Interacting with the Semantic Layer: Amplifying LLM Accuracy
There are numerous ways to interact with the semantic layer established, including business intelligence (BI) tools and APIs. Each of these approaches has its merits, but our primary focus here is to find its use case with the LLMs.
Once we have defined our cubes, we can utilize an API endpoint exposed by the Cube core to fetch the desired data. For further details on how to query Cube’s endpoints, refer to the Cube API documentation.
Contextualizing the LLM with Cube Definitions
In our exploration, we experimented with popular chat models from OpenAI and Claude Sonnet, both of which were already familiar with the cube’s definitions, including dimensions, measures, and time dimensions. The logical next step involves providing the LLM with the context of our current cube definitions. For this, we can utilize the endpoint “/v1/meta” to retrieve those details. More information can be found in the REST API reference.
Documenting the Approach
To ensure a smooth workflow, let’s document the steps we are undertaking:
- Set Up Cube Core
- Define Cube Definition Files
- Retrieve Metadata to Provide Context to the LLM
- Craft a System Prompt for the LLM to Generate Parameters for Cube Core Data Request API
- Initiate User Queries
System Prompt for LLM Engagement
Here’s the system prompt we utilized for guiding the LLM:
You are an expert in generating parameters for quering the cube semantic layer.
Generate json object to request data from cube semantic layer.
Do not assume existance of any field. If any unknown data is requested, just explain in reply why the user request cannot be translated to cube params.
If the user asks for current year data, generate parameters for until June of this current year 2024.
Do not give any assumed answers.
Do not join if not mentioned.
Here is the cube definition files used:
@CUBE_META_INFORMATION@
Recheck that you have generated properly.
Few examples:
user query: sales per person in this current year divided by month
json parameters: { "measures": [ "orders.total_sales" ], "timeDimensions": [ { "dimension": "orders.updated_at", "granularity": "month", "dateRange": "This year" } ], "order": { "orders.total_sales": "desc" }, "dimensions": [ "orders.email" ] }
user query: get me average order value grouped by city for this quarter, weekly.
json parameters: { "timeDimensions": [ { "dimension": "orders.updated_at", "granularity": "week", "dateRange": "This quarter" } ], "order": { "orders.updated_at": "asc" }, "dimensions": [ "orders.city" ], "measures": [ "orders.average_order_value" ] }
user query: get me average order value for each month in the year 2023 by city.
json parameters: {'timeDimensions': [{'dimension': 'orders.updated_at', 'granularity': 'month', 'dateRange': ['2023-01-01', '2023-12-31']}], 'dimensions': ['orders.city'], 'measures': ['orders.average_order_value']}
Please find the entire code here: https://github.com/valmi-io/semantic-layers-on-llm
Result Presentation via Streamlit
Finally, the outputs generated by the LLM can be displayed in a Streamlit app, showcasing how did the LLM interpret user requests and formulate data query parameters based on the defined cubes.
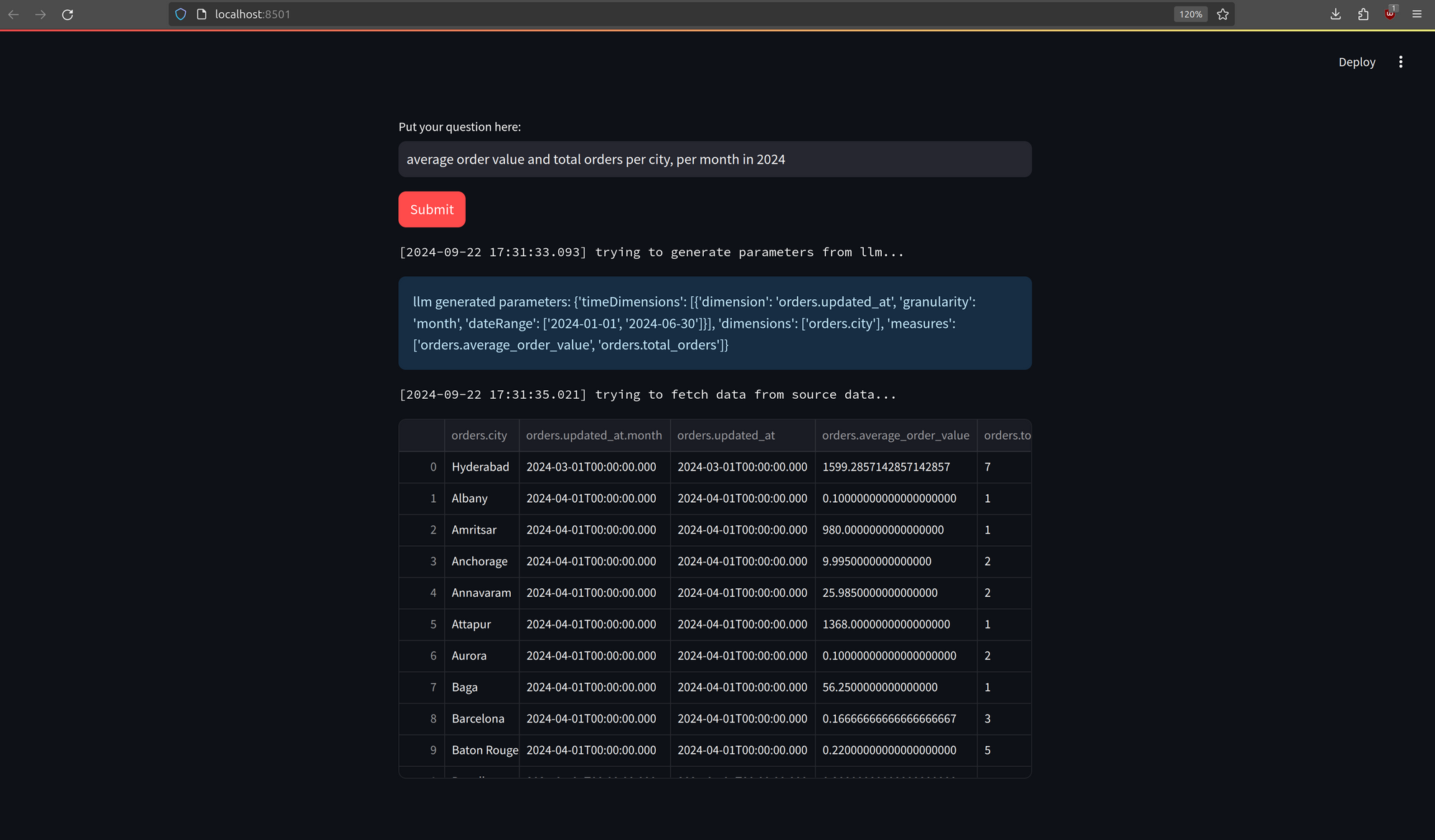
To truly harness the power of Large Language Models (LLMs) in conjunction with semantic layers, individuals must engage deeply with their own data by defining cubes, creating views, and evaluating the responses generated by the LLM for their specific use cases. One can also enrich the system prompt with additional information, such as parameter generation rules and acceptable values for those parameters.
We believe that we will be soon seeing development of benchmarks to assess the effectiveness of LLM capabilities when applied to semantic layers and, consequently, to various datasets. The time is ripe for realizing the full potential of LLMs in this context, and we are committed to playing our part in this exciting evolution.
The Future of Visualization: with AI
Imagine an AI-driven system where various specialized agents work together to create data visualizations from textual data. One agent transforms raw data into a format ready for a charting library. Another decides on the suitable type of graph based on the user query, while yet another integrates with the semantic layer to ensure context and relevance. Interesting use cases to experiment with.
Now it's your time to explore possibilites.
